Every New Beginning Comes From Some Other Beginning's End
I’m going to officially end my work on Snowdrop and Tangled… which is sad. I really, really, loved this project. I learned so many things. It kept me company on some of the long stretches of my cross-Canada walk. I abused the internet bandwidth of many of the nearly off-grid places we stayed, hammering away at a quantum computer from places like Manning Park, BC, Elkwater Lake Lodge & Resort, Alberta, and Consul, Saskatchewan. I am happy with how it turned out.

Me during the part of the walk where I went through Vancouver.
Today I put the current state of the game live at tangled-game.com. You can play against my quantum agents, and join a leaderboard. I am currently last.
There were A LOT of things that had to be done to get it this far. Probably the most fun of which was building my own version of AlphaZero. I also bought about 300 hours of D-Wave processor time. I used most of it!
The game itself isn’t very fun to play. It wasn’t designed to be. The point of it was to produce a system that could support the development of a superclassical agent. A superclassical agent is one that makes better decisions than any possible agent without access to quantum computation. You can read all about them here in my X-Prize competition submission.
Unfortunately I did not make the cut in that competition. After they’d made their decisions about who to include and not, they sent out a ‘scorecard’ that purported to explain their decisions. I was kind of relieved to see that it wasn’t that they thought this idea wasn’t good, it just wasn’t what they were looking for (which was new algorithms they could run on Google quantum computers). Oh well. I still think this idea is awesome!
The website hosts the same graphs as the ones in that X-Prize document, except for the biggest one (a mutated BuckyBall), which I left out of the website as everything about it was too big to do properly with my divided attention and lack of compute. Instead I used a moderately sized replacement — the very cool and interesting 10-vertex 15-edge Petersen graph — which I’ll talk about later in this post.
On the website I made the promise that if you can beat one of my quantum agents (AlphaZero Amara) on the Petersen graph I’ll send you a personalized “I beat a quantum agent” trophy. I know it’s possible to beat this agent (see the tournament results below) but personally I have never beaten it. Getting a draw is not that hard with some practice.
Anyway thanks to everyone who was following along with me on this journey. I feel good about the full arc and where it ended up. If you are interested in continuing the work of building superclassical agents, I’ve made three of my repos public; these are snowdrop-tangled-game-package, snowdrop-adjudicators, and snowdrop-tangled-agents. You can see how I approached the problem and what I did. If you want to learn all this stuff, start with the agents repo and follow my instructions on how to start. None of this was done with a view towards making it easy to follow and I’m not going to support it but there’s enough there to get you going.
Tangled on The Petersen Graph
For the website I added the Petersen graph. Here is what it looks like:
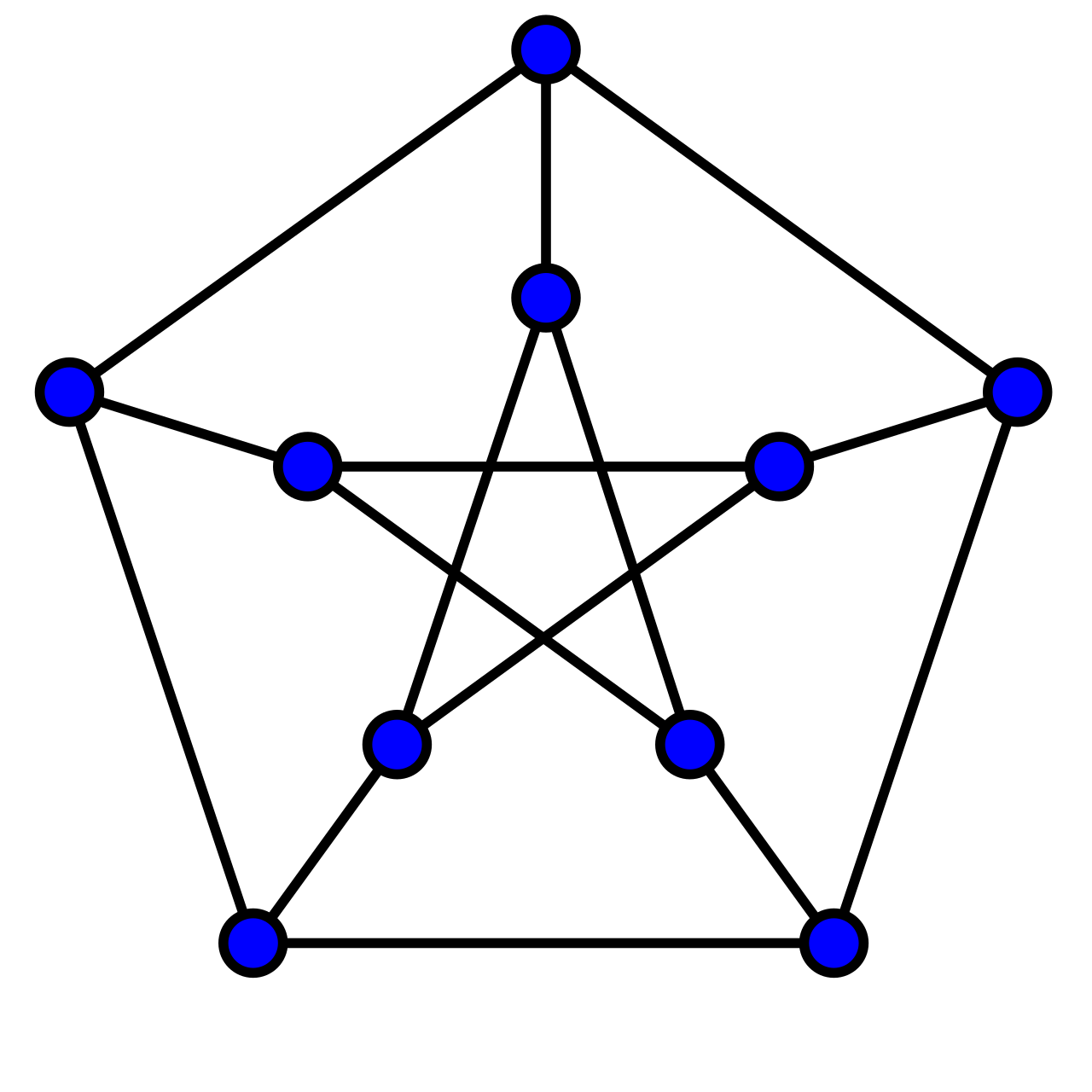
Look at how cool it is!!!!
This graph has 7,184,295 unique terminal states. This is small enough so that we can build a lookup table by solving each of them using a D-Wave quantum computer. I did exactly that — it took about 160 hours of QPU time! But I did it. By the way, I need to shout out the D-Wave people who were very supportive of me during the project. For example, I was running out of time for doing this enumeration and they helped me out. Also they were great about helping me through any technical challenges I had. I am really, really proud of what that company has turned into. They are world class!
Tournament Results For Different Agent Types
I entered nine different agents in a round-robin tournament. The results are shown in Figure 1 below. This is confusing so bear with me.
The Random agent just plays randomly.
The MCTS_X GT agents are pure Monte Carlo Tree Search agents using X rollouts, where the terminal states used are evaluated using the correct answers (the lookup table we built using the QC results). The MCTS_X SA agents are the same Monte Carlo Tree Search agents, but they use Simulated Annealing to evaluate terminal states. What this should mean is that at least for some terminal states they get who won wrong and therefore will be strictly worse for the same value of X. If you skip ahead to Figure 2, you will see that this is the case. MCTS_100 GT is better than MCTS_100 SA and MCTS_10 GT is better than MCTS_10 SA. This is exactly the effect that leads to superclassical agents!
The AlphaZero agents work the same way. AlphaZero_X GT uses X MCTS rollouts and ground truth for terminal state evaluation. AlphaZero_X SA uses X MCTS rollouts and simulated annealing for terminal state evaluation. Note the parameters and neural nets used for both were identical, the only difference was the terminal state evaluator. Again you can see the quantum advantage in Figure 2, and in fact the AlphaZero agent using ground truth with 10 rollouts was better that the AlphaZero agent using simulated annealing with 100 rollouts. This makes sense as doing more rollouts doesn’t help if the information you’re getting back about who won is wrong!
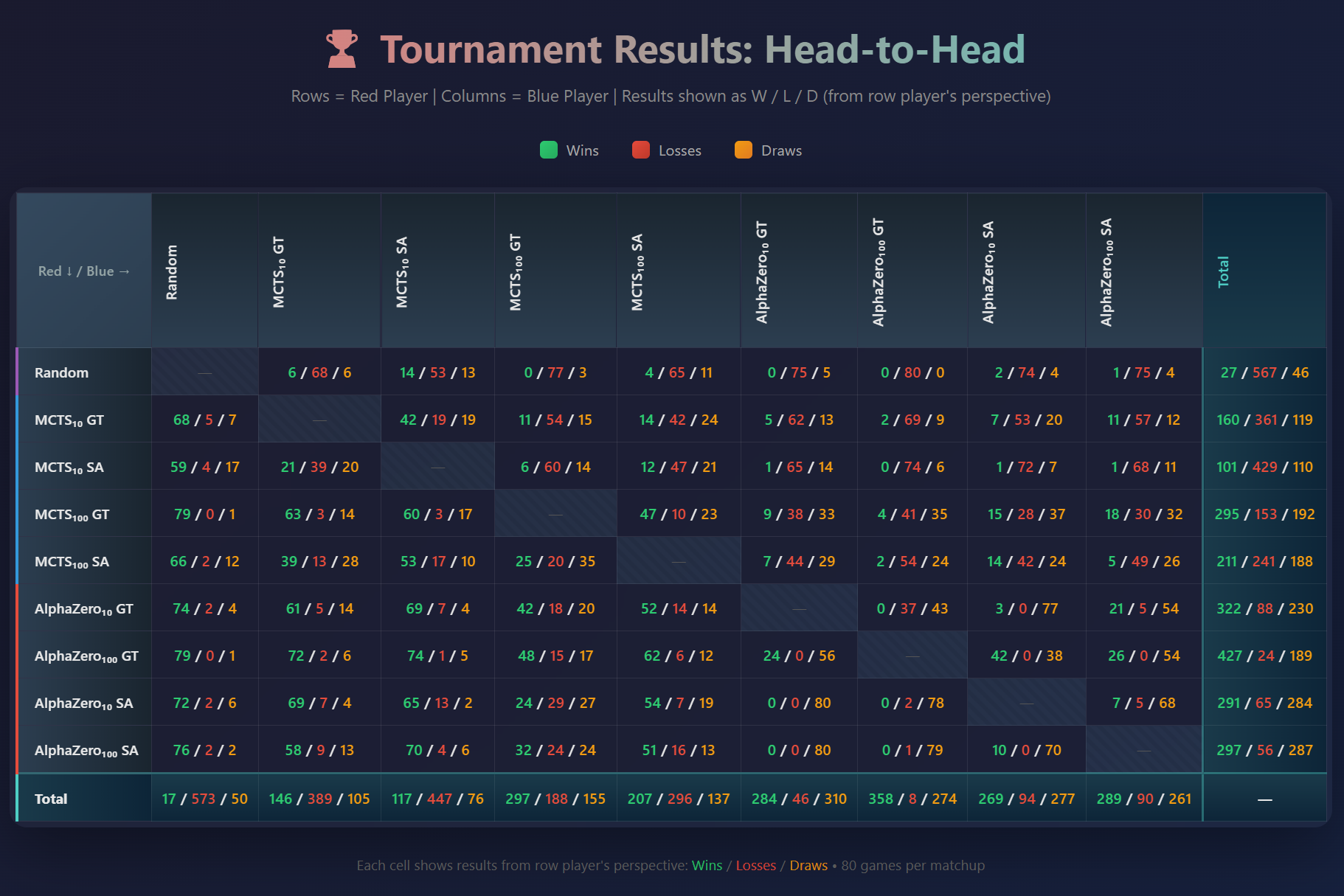
Figure 1: Full round-robin tournament results for all nine agents. The best agent, AlphaZero_100 GT, lost 24 games playing as red and 8 games playing as blue. Interestingly it did not lose any games to any of the other AlphaZero agents. This result probably means it just hasn’t been trained long enough to see the strategies the other agents are using, and if I kept training it, it would probably at some point become unbeatable.
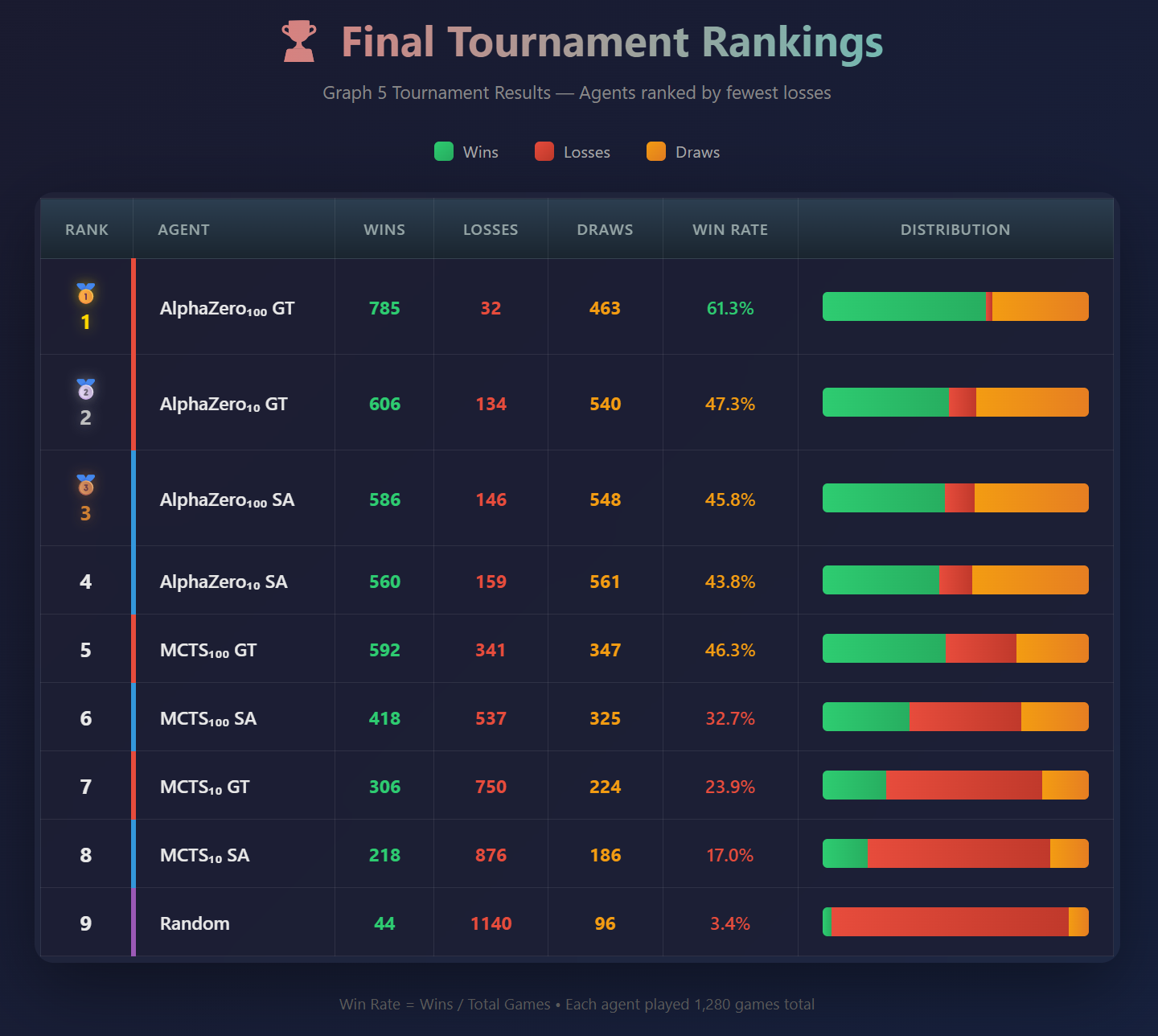
Figure 2. Ranked agents from the tournament.
The AlphaZero_100 GT agent (the winner of this tournament) is the one I call AlphaZero Amara on the website (AlphaZero Andy is the AlphaZero_10 GT agent), and the one you have to beat to get a trophy. Obviously increasing the number of rollouts would the agent stronger, as would continuing to train it longer. For the first there’s a practical limit on the amount of time a player is willing to wait for the agent to make a move, and I’m hosting this thing on railway.com with basic processors. I tried increasing rollouts to 1,000 and it took 5 and a half minutes to make a move, which is not OK, so I went back down to 100 which still takes a while (about half a minute) but that’s not ridiculous. For training the neural net more, I could do that I guess but I think I made my point and it is kind of nice to know that the thing CAN be beat (it lost playing both red and blue a bunch of times to underpowered MCTS agents).
Final Thoughts
This has been a lot of fun. I hope you liked following along. I will be a bit sad to end the project. But I am now working on something much bigger and more impactful. I have always wanted to create agents with general intelligence. The new project is a new beginning, and this one is done.
I hope some of the faithful blog followers will be able to beat AlphaZero Amara so I can get you a trophy!